リスト(list)#
Jupyter Notebook ファイルの準備
このノートを学習するために、「list.ipynb」 という名前で Jupyter Notebook のファイルを作成してください。
このノートの練習問題
内容を一通り確認できたら、以下の練習問題に取り組むことでご自身の理解度をチェックしてください。
練習問題:練習問題:リスト | データ構造
リストは複数のデータを順番に格納できるデータ構造です。Python のリスト(list クラス)は、 Java のコレクションのリスト( ArrayList や LinkedList クラス)と比べて、より柔軟性があります。このノートを通して、Python におけるリストの基本的な扱い方を学びましょう。
1. リストの基本操作#
1-1. リストを作成する#
リストの最もシンプルな作成方法は角括弧([]) を用いたリテラルです。次のように、[] 内にカンマ区切りで各要素を指定します。
[要素1, 要素2, 要素3, 要素4, ...,]
[要素1, 要素2, 要素3, 要素4, ...] # 最後のカンマは省略できる
[] # 要素を書かない場合は空のリストが作成される
リストには、オブジェクトの実体ではなく、オブジェクトを参照するための値(参照値)が要素として格納されます。
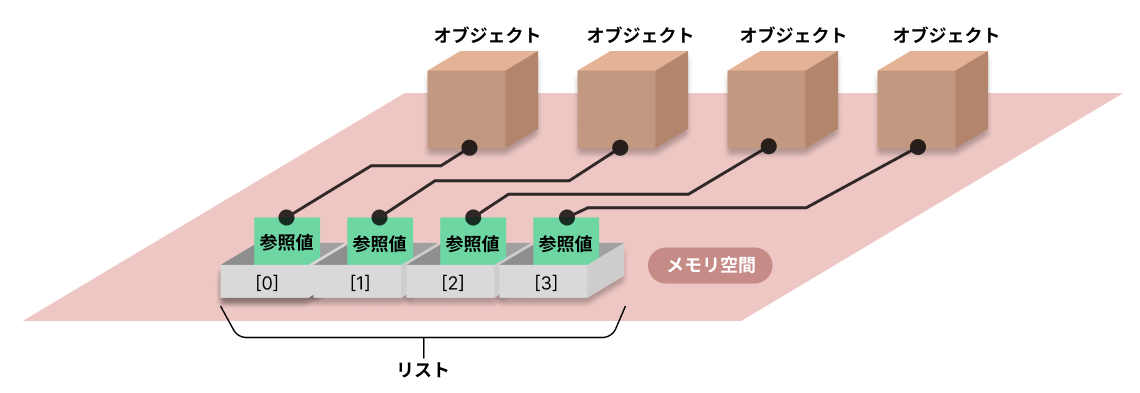
また、Java のような型に厳格な言語と違い、格納する要素の型を宣言する必要はありません。それだけでなく、同じリストに複数の異なる型のオブジェクトを格納できます。
以下の例では、同じリストに int, float, str, bool とそれぞれ異なる型のオブジェクトを格納しています。
li = [1, 2.0, 'a', True]
print(li)
[1, 2.0, 'a', True]
また、リストは別のリストを要素にもつことができます。要素となる各リストの長さ(リストに含まれる要素の数)を統一する必要はありません。
# 2つめと3つめの要素が長さの違うリスト
li = ['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
print(li)
['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
1-2. リストの長さを取得する#
リストの長さ(要素数)を取得するには、Python に標準で組み込まれている len 関数を使います。len 関数にリストを渡して呼び出すと、そのリストの長さを表す整数値が返ってきます。
li = [1, 2.0, 'a', True]
length = len(li)
print(length) # 4
4
1-3. リスト内の要素を取得する#
リストの要素は、先頭から順番に一列で並んでいます。そのため、各要素は先頭を「0」とするインデックスを使い、参照することができます。参照には Java や JavaScript と同様に、ブラケット表記法で [] 内にインデックスを指定します。指定したインデックスで要素が存在しない場合は、例外 IndexError が送出されます。
li = [1, 2.0, 'a', True]
# リストの各要素はブラケット表記法でインデックスを指定して参照できる
print(li[0]) # 1
print(li[1]) # 2.0
print(li[2]) # 'a'
print(li[3]) # True
# 以下のコードを有効にすると、該当する要素がないため IndexError 例外が送出される
# print(li[4])
1
2.0
a
True
また、次のように入れ子構造になっているリストにおいて、内側のリストの要素を参照する場合は、その階層に合わせて [] を連続して書きます。
li = ['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
user_name = li[1]
print(user_name) # ['Taro', 'Shonan']
user_first_name = li[1][0] # user_name[0]と同じ
print(user_first_name) # 'Taro'
['Taro', 'Shonan']
Taro
さらに、インデックスとして、負の整数値も指定できます。その場合、下図のように、末尾の要素を -1 として、先頭に向かって絶対値が大きくなります。
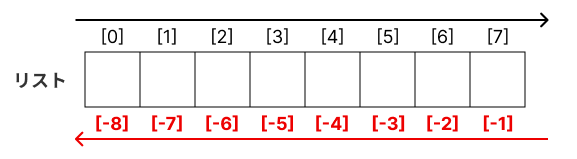
これを利用すると、長さの分からないリストから末尾の要素を取得するときに、len 関数を使うよりも、コードを簡潔に記述できます。
li = [0, 1, 2, 3, 4, 5]
# len 関数を利用して末尾の要素を取得する場合
print(li[len(li)-1]) # 5
# 負のインデックスを指定して末尾の要素を取得する場合
print(li[-1]) # 5
5
5
1-4. リスト内の既存要素を変更する#
リスト内の既存要素を、別のオブジェクトに変更したい場合、変数へのオブジェクトの再代入と同じように、代入演算子(=)を使います。代入演算子の左辺に、ブラケット表記法を用いて再代入先のインデックスを指定し、右辺に変更後のオブジェクトを指定します。
li = [1, 2.0, 'a', True]
li[3] = False
print(li) # [1, 2.0, 'a', False]
[1, 2.0, 'a', False]
1-5. リストから要素を削除する#
リスト内の要素は del 命令で削除できます。del に続けて、削除したいリストの要素をブラケット表記法で指定します。このとき、削除した要素の後にある要素はインデックスがひとつずつ前に移動します。
li = [1, 2.0, 'a', True]
del li[1] # インデックス「1」の要素を削除
print(li) # [1, 'a', True]
print(li[1]) # a
[1, 'a', True]
a
ただし、リストから削除される要素はあくまでもオブジェクトの参照値です。参照先のオブジェクトの実体は削除されません。そのため、以下の例では、del 命令でリストから要素が削除された後も、同じオブジェクトを参照している変数からオブジェクトの実体へアクセスできています。
obj = 'Python' # 変数 obj には文字列オブジェクトへの参照値が代入される
li = [obj] # リストに格納されるのはあくまでも文字列オブジェクトへの参照値
del li[0] # 削除対象は格納された参照値であり、参照先の文字列オブジェクトは削除されない
print(obj) # Python
Python
1-6. リストから繰り返し要素を取得する#
次のコードは、前のノートで紹介した for 文を使い、 range クラスと len 関数で調べたリストの長さから、インデックスを順番に指定し、要素を繰り返し取得しています。
li = [0, 1, 2, 3]
for i in range(len(li)):
print(li[i])
0
1
2
3
Python では、上のようなインデックスを用いた方法以外に、for 文の in キーワードの後にリストを指定し、要素を順番に取得することができます。
li = [0, 1, 2, 3]
for element in li: # 変数 element には先頭から順番に要素が代入される
print(element)
0
1
2
3
このように、 in キーワードに続けて指定できるオブジェクトがもつ性質を、 Python では 繰り返し可能 と表現します。 range オブジェクトやリストだけでなく、後のノートで紹介するタプルや集合、辞書はすべて繰り返し可能なオブジェクトであり、同じように for 文で繰り返し要素を取得することができます。
ここまでがリストの基本的な操作方法になります。次のセクションからは、より高度なリストの操作方法を紹介します。
2. リストのスライス#
下図のように、リストから単一の要素ではなく、複数の要素を集め、部分的なリストとして取得したい場合、これから説明するスライスが大変便利です。
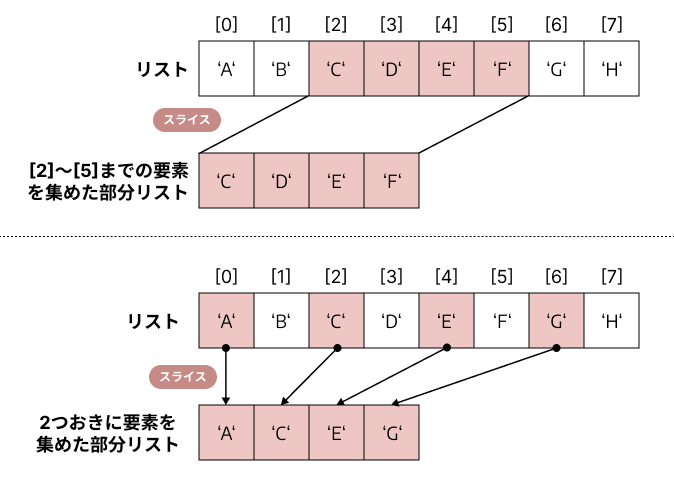
2-1. スライスを用いた要素の取得#
スライスでは、リストから取得する要素の範囲を次の 3 つの整数値で定めます。
開始位置
終了位置(※ 終了位置と同じインデックスの要素は取得範囲に含まれません。)
ステップ(※ 2 つおきや3 つおきなどで要素を取得したい場合に指定します。)
スライスは単一の要素を取得するときと同様に、ブラケット表記法を用いて記述します。上の 3 つの整数値を [] 内にコロン(:)で区切り、順番に指定します。
リストの変数名[開始位置:終了位置:ステップ]
例えば、リスト ['a', 'b', 'c', 'd', 'e'] から、 'c' と 'd' の 2 つの要素を ['c', 'd'] と、部分リストとして取得する場合、スライスを用いて次のように記述します。
li_origin = ['a', 'b', 'c', 'd', 'e']
# 開始位置:2, 終了位置:5, ステップ:1 でスライス
li_partial = li_origin[2:4:1]
print(li_origin) # ['a', 'b', 'c', 'd', 'e']
print(li_partial) # ['c', 'd']
['a', 'b', 'c', 'd', 'e']
['c', 'd']
また、同じリストから要素をひとつ飛ばしで集めた部分リスト ['a', 'c', 'e'] を取得する場合は、次のように記述します。
li_origin = ['a', 'b', 'c', 'd', 'e']
# 開始位置:0, 終了位置:5, ステップ:2 でスライス
li_partial = li_origin[0:5:2]
print(li_origin) # ['a', 'b', 'c', 'd', 'e']
print(li_partial) # ['a', 'c', 'e']
['a', 'b', 'c', 'd', 'e']
['a', 'c', 'e']
このように、スライスによる要素の取得は元のリストを変更しません。元のリストがもつ要素の参照値をコピーして、それらを要素としてもつ新しいリストオブジェクトを作成します。
また、開始位置、終了位置、ステップのいずれも省略可能な書き方があり、省略した場合はそれぞれ次の値が代わりに使われます。
開始位置:0
終了位置:末尾の要素のインデックス + 1
ステップ:1
以下は省略した書き方の一覧です。ステップを省略する場合を除いて、コロン(:)は省略できないため気を付けてください。
変数名[開始位置:] # ステップの手前の区切りとしてのコロン(:)は不要
変数名[:終了位置] # ステップの手前の区切りとしてのコロン(:)は不要
変数名[開始位置::ステップ]
変数名[:終了位置:ステップ]
変数名[::ステップ]
Python ではスライスを活用することで、リストをより柔軟に操作できます。実際に様々なパターンでスライスを行ったものが以下の例です。
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 元のリスト
# インデックスが 3 ~ 6 の要素を取得
print(li[3:7]) # [3, 4, 5, 6] ※ 7 は含まれないので注意
# インデックスが 4 以上の要素を取得
print(li[4:]) # [4, 5, 6, 7, 8, 9]
# インデックスが 4 未満の要素を取得
print(li[:4]) # [0, 1, 2, 3]
# インデックス 4 から末尾まで 2 つおきに要素を取得
print(li[4::2]) # [4, 6, 8]
# 先頭からインデックス 7 未満まで 2 つおきに要素を取得
print(li[:7:2]) # [0, 2, 4, 6]
# 先頭から末尾まで 2 つおきに要素を取得
print(li[::2]) # [0, 2, 4, 6, 8]
[3, 4, 5, 6]
[4, 5, 6, 7, 8, 9]
[0, 1, 2, 3]
[4, 6, 8]
[0, 2, 4, 6]
[0, 2, 4, 6, 8]
ステップには負の値も指定できます。ステップに負の値を指定すると、末尾から先頭に向かって要素を集めます。よくある使い方として、ステップに -1 を指定し、要素を逆順に並び替えた新たなリストを作成することがあります。以下はそのコード例です。
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
li_reversed = li[-1::-1]
# 開始位置の -1 は省略可能で、 li_reversed = li[::-1] でも同じリストが得られる
print(li_reversed) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
2-2. スライスを用いた要素の変更や削除#
スライスはリストから要素を取得するときだけでなく、リストの一部を別のリストがもつ要素に置き換えたり、要素を一括して削除したりするときにも使えます。
リストを部分的に別のリストの要素に置き換える#
代入演算子 = の左オペランドに置き換えたい部分をスライスで表記し、右オペランドに置き換える要素をもつリストを指定します。
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 元のリスト
# インデックス 3 ~ 6 を別のリストの要素に置き換える
li[3:7] = [10, 11, 12]
print(li) # [0, 1, 2, 10, 11, 12, 7, 8, 9]
# [0, 1, 2, [10, 11, 12], 7, 8, 9] とはならない
[0, 1, 2, 10, 11, 12, 7, 8, 9]
このとき、左辺のスライスで指定された範囲の要素の数と、右辺のリストの要素の数は一致していなくても構いません。スライスの範囲が抜けて、そこに新たな要素がまるっと挿入されるような結果になります。
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 元のリスト
li[3:7] = [10, 11, 12, 13] # スライスの指定範囲よりも要素数が多いリストを指定
print(li) # [0, 1, 2, 10, 11, 12, 13, 7, 8, 9]
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 元のリスト
li[3:7] = [10, 11] # スライスの指定範囲よりも要素数が少ないリストを指定
print(li) # [0, 1, 2, 10, 11, 7, 8, 9]
[0, 1, 2, 10, 11, 12, 13, 7, 8, 9]
[0, 1, 2, 10, 11, 7, 8, 9]
リストから部分的に要素を削除する#
スライスと del 命令を組み合わせると、要素を一括で指定して削除できます。
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
del li[3:7] # インデックス 3 ~ 6 の要素を削除
print(li) # [0, 1, 2, 7, 8, 9]
[0, 1, 2, 7, 8, 9]
3. メソッドを利用したリストの操作#
Pythonでは、メソッドを使ってリストを操作することもできます。これまでに紹介してきた操作方法と比べて、メソッドを使う方がより適当な場合もあるため、特長を押さえて、状況に応じて使い分けられるようになりましょう。
3-1. 等しい値をもつ要素のインデックスを取得する#
index(obj) メソッドは、() 内に指定したオブジェクトと等しい値(※)をもつ要素を、リストの先頭から探索し、最初に見つかった要素のインデックスを返します。等しい値をもつ要素が見つからなかった場合は、ValueError 例外が送出されます。
Note
※ 「等しい値をもつ」とは == 演算子の評価結果が True になることを指しています。同じオブジェクトであることを指している訳ではないので気を付けてください。もちろん同じオブジェクトであれば、== の評価結果が True になるため一致します。
li = [1, 2, 3 ,4, 3]
# 同じ値をもつ最初の要素のインデックスを取得する
print(li.index(3)) # 2
# 以下を有効にすると、同じ値をもつ要素がないため ValueError が送出される
# print(li.index(5))
2
3-2. リストの末尾に要素を追加する#
append(obj) メソッドは、() 内に指定したオブジェクトを、リストの末尾に追加します。
li = ['a', 'b', 'c', 'd']
li.append('e')
print(li) # ['a', 'b', 'c', 'd', 'e']
['a', 'b', 'c', 'd', 'e']
3-3. 位置を指定してリストに要素を追加する#
末尾以外の位置に新たな要素を追加したい場合、 insert(index, obj) メソッドを使います。このメソッドでは、 index で指定した要素の直前に obj が新たな要素として挿入されます。このとき、元々 index の位置にあった要素や、それ以降の要素はひとつずつ末尾の方向に移動します。
li = [0, 1, 2, 3, 4, 5]
li.insert(2, 'a') # インデックス 2 の要素の前に追加する
print(li) # [0, 1, 'a', 2, 3, 4, 5]
li.insert(0, 'b') # index に 0 を指定すると先頭に要素が追加される
print(li) # ['b', 0, 1, 'a', 2, 3, 4, 5]
[0, 1, 'a', 2, 3, 4, 5]
['b', 0, 1, 'a', 2, 3, 4, 5]
3-4. 位置を指定してリストから要素を削除する#
pop(index) メソッドは、 指定したインデックスの位置にある要素をリストから取り除き、さらに取り除いた要素を戻り値として返します。また、index が省略された場合は、リストの末尾の要素を取り除いて、戻り値として返します。 index がリストの範囲外であった場合は例外(IndexError)が送出されます。
li = [0, 1, 2, 3, 4]
num = li.pop(2) # インデックスが 2 の要素を削除
print(num ,li) # 2 [0, 1, 3, 4]
2 [0, 1, 3, 4]
li = [0, 1, 2, 3, 4]
num = li.pop() # index が省略された場合は末尾の要素を削除
print(num, li) # 4 [0, 1, 2, 3]
4 [0, 1, 2, 3]
3-5. 等しい値をもつ要素をリストから削除する#
remove(obj) メソッドは、指定されたオブジェクトと等しい値をもつ要素を先頭から探索し、最初に一致した要素をリストから削除します。もし、リスト内に等しい値をもつ要素が見つからない場合は、 例外(ValueError) が送出されます。
li = ['a', 'b', 'c' ,'b', 'c']
li.remove('c') # 最初に 'c' に一致する要素を削除
print(li) # ['a', 'b', 'b', 'c']
['a', 'b', 'b', 'c']
3-6. リストからすべての要素を削除する#
clear() メソッドは、リスト内の全ての要素を削除します。呼び出し後は、リスト自体が削除されるのではなく、要素をもたない空のリストになります。
li = [0, 1, 2, 3, 4]
li.clear()
print(li) # [] : 空のリスト
[]
3-7. 要素を逆順に並べる#
リストの要素を逆順に並べ替えたいときは reverse() メソッドを使います。ただし、 reverse() メソッドは呼び出し元のリストの構造を変えてしまうので注意してください。
# reverse() メソッドは○○なので注意
li = [1, 2, 3, 4, 5]
li.reverse()
print(li) # [5, 4, 3, 2, 1]
li.reverse() # もう一度 reverse() メソッドを呼び出すと元に戻る
print(li) # [1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
[1, 2, 3, 4, 5]
元のリストは残したまま、要素を逆順にしたリストを新たに用意したい場合は、reverse() メソッドの代わりに、先に紹介したスライスや後のノートで紹介する reversed 関数を使うようにしてください。
# スライスの場合は新しいリストが作成されるため元のリストに影響はありません
li = [1, 2, 3, 4, 5]
li_reversed = li[::-1]
print(li_reversed) # [5, 4, 3, 2, 1]
print(li) # [1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
[1, 2, 3, 4, 5]
3-8. 等しい値をもつ要素を数える#
count(obj) メソッドは、引数に渡したオブジェクトと等しい値を持つ要素を調べ、その個数を戻り値として返します。
li = [1, 2, 2, 3, 3, 3]
print(li.count(2)) # 2
print(li.count(3)) # 3
2
3
3-9. リストをコピーする#
変数から変数への代入演算子 = を用いた代入ではリスト自体の参照値をコピーするため、以下の 2 つの変数はどちらも同じリストオブジェクトを参照することになります。
li_origin = [1, 2, 3, 4, 5]
li_copied = li # 参照値がコピーされる
print(li_origin is li_copied) # True : 変数 li と li_copied は同一のオブジェクトを参照している
False
もし、リストの全ての要素(の参照値)をコピーした新たなリストを作成したい場合は copy() メソッドを使います。
li_origin = [1, 2, 3, 4, 5]
li_copied = li_origin.copy()
print(li_copied)
print(li_origin is li_copied) # False: li と li_copied は中身は同じだがそれぞれ異なるオブジェクトを参照している
[1, 2, 3, 4, 5]
False
ただし、copy() メソッドは浅いコピー(shallow copy)を返すことに注意してください。浅いコピーは、各要素が参照するオブジェクトは複製せず、その参照値をコピーします。そのため、新しく作成されたリストの各要素はコピー元のリストの各要素と同じオブジェクトを指すことになります。
li_origin = ['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
li_copied = li_origin.copy()
print(li_copied)
print(li_origin is li_copied) # False : リストのコピーは新しいオブジェクトとして作成される
# copy メソッドは各要素の参照値をコピーしているため、
# コピー先とコピー元で同じインデックスの要素は、
# どちらも同じオブジェクトを参照している
(li_origin[1] is li_copied[1]) # True : ['Jiro', 'Shonan'] という同じリストオブジェクトを参照している
['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
False
True
リストの深いコピー
もし、要素の浅いコピーではなく、要素のオブジェクト自体を複製する深いコピー(deep copy)を行いたい場合は、 copy モジュールの deepcopy 関数を使います。複数階層の入れ子構造になっているリストなど、複雑なデータ構造であっても、すべての要素が参照するオブジェクトが再帰的に複製されます。Python では、こうした便利な関数やクラスが、独立したモジュールとして用意されています。モジュールの仕組みや構文については後のノートで詳しく説明します。
import copy # copy モジュールをインポート
li_origin = ['10001', ['Taro', 'Shonan'], [1990, 1, 10]]
li_deepcopied = copy.deepcopy(li_origin) # 深いコピーを作成
print(li_deepcopied)
print(li_origin is li_deepcopied) # False
print(li_origin[1] is li_deepcopied[1]) # False:各要素のオブジェクトも複製されている
4. リストのアンパック#
リストを代入した変数の名前の先頭にアスタリスク(*)を付与すると、参照しているリストの要素をその場で展開することができます。これをリストの アンパック と呼びます。以下の例では、print 関数の呼び出しで、変数をそのまま渡した場合とアンパックを行い渡した場合の出力結果の違いを確認しています。
li = [1, 2.0, 'a', True]
# リストが代入された変数をそのまま print 関数に渡すと
# 「リストオブジェクト」として出力される
print(li) # [1, 2.0, 'a', True] : [] が付いているためリストであることが分かる
# 変数名の先頭にアスタリスクを付けて要素を展開(アンパック)して渡すと
# print(1, 2.0, 'a', True) と同じ処理になる
print(*li) # 1 2.0 a True : [] や , がなく、個々の要素が並べて出力されていることが分かる
[1, 2.0, 'a', True]
1 2.0 a True
4-1. 複数のリストを結合する#
アンパックはその場で要素を展開するため、次のように記述することで、2つのリストの要素を結合した新たなリストを作成できます。
li_1 = ['a', 'b', 'c']
li_2 = ['d', 'e', 'f']
# アンパックを用いたリストの結合
li_joined = [*li_1, *li_2]
print(li_joined) # ['a', 'b', 'c', 'd', 'e', 'f']
# アンパックを用いない場合は二次元リストとなる
li_not_unpack = [li_1, li_2]
print(li_not_unpack) # [['a', 'b', 'c'], ['d', 'e', 'f']]
['a', 'b', 'c', 'd', 'e', 'f']
[['a', 'b', 'c'], ['d', 'e', 'f']]
4-2. 要素を分割して変数に代入する#
アンパックは、各要素をそれぞれ異なる変数に代入するときにも便利です。アンパックを用いた変数への代入は次のように記述します。
変数名1, 変数名2, 変数名3, ... = リストの変数名 # 変数名の先頭にアスタリスクは不要
# アンパックによって以下と同じ記述になる
# 変数名1, 変数名2, 変数名3, ... = リストの変数名[0], リストの変数名[1], リストの変数名[2], ...
この場合、リストを代入した変数名の先頭にアスタリスクは必要ありません。= の左オペランドの左端に宣言した変数に、リストの先頭の要素が代入され、右側に向かって各要素が順番に代入されます。このようなアンパックを利用した代入の仕方は分割代入とも呼ばれます。
ただし、分割代入では、変数の数をリストの要素数に合わせなければなりません。数が一致しない場合は、例外(ValueError)が送出されます。
例えば、4 つの要素をもつリストにおいて、すべての要素をそれぞれ異なる変数に代入したい場合は次のように記述します。
li = [1, 2.0, 'a', True]
num_1, num_2, char, boolean = li # 変数はリストの要素順に記述する
print(num_1, num_2, char, boolean)
# 以下を有効にすると、変数の数と要素の数が一致しないため ValueError が送出される
# num_1, num_2, char = li
1 2.0 a True
また、複数の要素を部分リストとしてまとめ、変数に代入することもできます。その場合、変数名の先頭にアスタリスクを付与します。以下の例では、先頭と末尾の要素を除いた中間の要素をひとつのリストにまとめて、変数に代入しています。
# 以下のように = の右オペランドは直接リテラルを記述しても良い
start, *middles, end = [1, 2, 3, 4, 5] # middles には [2, 3, 4] のリストが代入される
print(start) # 1
print(middles) # [2, 3, 4]
print(end) # 5
1
[2, 3, 4]
5
ただし、このようにアスタリスクを付けた変数は 1 つだけしか宣言できません。上の例のように「先頭と末尾を除いた中間の要素」をまとめて代入する以外では、「先頭とそれ以外」や「末尾とそれ以外」に分けて代入する記述パターンがあります。
# 先頭とそれ以外
start, *rest = [1, 2, 3, 4, 5]
print(start, rest) # 1 [2, 3, 4, 5]
# 末尾とそれ以外
*rest, end = [1, 2, 3, 4, 5]
print(rest, end) # [1, 2, 3, 4] 5
# 以下を有効にすると SyntaxError が発生
# start, *rest_1, *rest_2 = [1, 2, 3, 4, 5]
1 [2, 3, 4, 5]
[1, 2, 3, 4] 5
4-3. for 文と分割代入を組み合わせる#
二次元リストから内側のリストの要素を繰り返し取得したい場合、for 文を用いて先に外側のリストから内側のリストを繰り返し取得し、次にループブロック内でブラケット表記法を使い、内側のリストから個別に要素を取得します。以下のコードは、この手順でユーザー情報を表す二次元リストから、各ユーザーのIDと名前を取得し、print 関数で出力しています。
users = [
['user_001', 'Ushijima'],
['user_001', 'Takai'],
['user_001', 'Okita'],
]
for u in users:
u_id = u[0]
u_name = u[1]
print(u_id, u_name)
user_001 Ushijima
user_001 Takai
user_001 Okita
このコードは、分割代入を用いることで、より簡潔に記述することができます。具体的には for キーワードの後に、カンマ区切りで変数名を並べて書きます。
users = [
['user_001', 'Ushijima'],
['user_001', 'Takai'],
['user_001', 'Okita'],
]
for u_id, u_name in users:
print(u_id, u_name)
user_001 Ushijima
user_001 Takai
user_001 Okita
このように余分な記述を減らせるため、上手く活用してください。
5. リストと演算子#
リストは、様々な演算子を用いて操作することもでき、メソッドを使うよりもコードを簡潔に記述できる場合があります。
5-1. 等しい値をもつ要素の有無を調べる#
リスト内に等しい値をもつ要素が存在しているかどうかを調べるには、リストの index(obj) メソッドが使えます。以下の例では、 index メソッドと例外処理の try-except 文を組み合わせて、ValueError が送出されたかどうかで存在の有無を調べています。
li = ['a', 'b', 'c', 'd']
target = 'e'
try:
li.index(target) # 存在しない場合は ValueError がスローされる
except ValueError:
print(f'{target}はリスト内に存在しません。')
else:
print(f'{target}はリスト内に存在しています。')
eはリスト内に存在しません。
実際にはこのように回りくどいことをする必要はありません。 in 演算子や not in 演算子を使うと簡単に調べることができます。
obj in list:objと等しい値をもつ要素がlistにあればTrueを返し、なければFalseを返します。obj not in list:in演算子と反対の結果を返します。objと等しい値をもつ要素がlistになければTrueを返し、あればFalseを返します。
in 演算子や not in 演算子の評価過程では、ひとつひとつの要素に対して == 演算子や != 演算子を用いた比較が行われています。先ほどのコードは、これらの演算子に置き換えると次のように記述できます。
li = ['a', 'b', 'c', 'd']
target = 'e'
# in 演算子に置き換えた例
if target in li:
print(f'{target}はリスト内に存在しています。')
else:
print(f'{target}はリスト内に存在しません。')
# not in 演算子に置き換えた例
if target not in li:
print(f'{target}はリスト内に存在しません。')
else:
print(f'{target}はリスト内に存在しています。')
eはリスト内に存在しません。
eはリスト内に存在しません。
5-2. 2 つのリストを結合する#
リストどうしは + 演算子で簡単に結合することができます。結合後のリストは、元の 2 つのリストとは異なるオブジェクトとして作成されます。
li_1 = [1, 2, 3]
li_2 = [4, 5]
li_joined = li_1 + li_2
print(li_joined) # [1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
+ 演算子を使う以外には、アンパックとリテラルを組み合わせた結合がありました。こちらは、後のノートで説明するタプルとリストという異なるオブジェクトがもつ要素を結合して新たなリストを作成したい場合にも使えます。
li_1 = [1, 2, 3]
li_2 = [4, 5]
tup = (6, 7) # タプル
# + 演算子ではタプルとリストの異なる種類のオブジェクトどうしを結合できないが、
# アンパックとリテラルの組み合わせならそれが可能
li_joined = [*li_1 ,*li_2, *tup]
print(li_joined) # [1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 6, 7]
5-3. 元のリストを指定した回数繰り返し連結した新しいリストを作成する#
* 演算子を使うと、元のリストを指定した回数繰り返し連結した新しいリストを作成できます。一定の規則性で要素が並んだリストを用意したいときに便利です。
li = [1, 2, 3]
li_repeated = li * 3 # 元のリストを3回繰り返し連結したリストを作成
print(li_repeated) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
[1, 2, 3, 1, 2, 3, 1, 2, 3]
5-4. 2つのリストを比較する#
Python では、 2 つのリストが等しいかどうか、言い換えると等しい値をもつ要素を同じ順序でもつかどうかを判定するときに、for 文を用いて各要素を順番に取得して比較する必要はありません。 == 演算子や != 演算子で簡単に判定できます。
==: 2 つのリストが等しい要素を同じ順序でもつかどうかを判定します。!=:==と反対の評価をします。
li_1 = [1, 2, 3, 4, 5]
li_2 = [1, 2, 3, 4, 5] # li_1 と等しい要素を同じ順序でもつ
li_3 = [5, 4, 3, 2, 1] # li_1 と等しい要素をもつが、順序が違う
print(li_1 == li_2) # True
print(li_2 == li_3) # False
print(li_1 != li_2) # False
print(li_2 != li_3) # True
True
False
False
True
6. リストの内包表記#
ここまでの説明では、[] を用いたリテラルでリストを作成してきました。しかし、この方法では要素をひとつずつ書かなければならないため、要素数が多くなると、それだけコードの記述量が増えてしまいます。そこで、1 から 20 までの整数値のように、ある一定の規則で要素が並ぶ場合、for 文とリストの append メソッドを組み合わせるなど、代わりの手段を考えることでしょう。
li = [] # 空のリストを作成
for n in range(1, 21):
li.append(n)
print(li)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
Python には、上と同じ処理をより簡潔に記述できる 内包表記 という便利な表記法が用意されています。
6-1. 内包表記の基本#
まずは具体例から入りましょう。上の例を内包表記に置き換えたものが以下のコードです。内包表記を使うと、このように 1 文にまとめることができます。
li = [n for n in range(1, 21)] # 内包表記
print(li)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
内包表記は分解すると、次のような構造になっています。
[ 式 for 変数名 in 繰り返し可能オブジェクト]
# 上の例ではそれぞれ次のようになっていた
# 式: n
# 変数: n
# 繰り返し可能オブジェクト:range(1, 21) の戻り値
for の前にあるのは「式」です。この式の評価は for による反復処理の各ループごとに行われ、その結果が新たに作成されるリストの要素として順番に追加されます。通常この式は for の後に指定した変数を用いて表します。
続く for 変数名 in 繰り返し可能オブジェクト の記述の仕方は、for 文と同じです。in の後に指定する繰り返し可能オブジェクトは、リストや range オブジェクトなどが該当します。「繰り返し可能」のような、オブジェクトがもつ性質については、別のノートで詳しく説明します。
また、for の前には様々な式が指定できます。例えば、 1 から 20 までの整数値とそれぞれを 3 で割った余りを [整数値, 3で割った余り] のリスト形式でまとめ、新たなリストの要素として順番に格納する場合、次のように記述します。
# ▼ [n, n % 3] が要素となるリストを作成する内包表記
li = [[n, n % 3] for n in range(1, 21)]
print(li)
[[1, 1], [2, 2], [3, 0], [4, 1], [5, 2], [6, 0], [7, 1], [8, 2], [9, 0], [10, 1], [11, 2], [12, 0], [13, 1], [14, 2], [15, 0], [16, 1], [17, 2], [18, 0], [19, 1], [20, 2]]
6-2. 多重ループ構造をもつ場合の内包表記#
for 文が入れ子になった次のようなコードも、内包表記を使い、1 文で表すことができます。
points = []
for x in range(3):
for y in range(3):
points.append([x, y])
print(points)
# ▲ [[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
[[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
この場合、[] 内に外側のループから順番に、for-in を記述します。
[ 式 for 外側ループの変数名 in 外側ループの繰り返し可能オブジェクト
for 内側ループの変数名 in 内側ループの繰り返し可能オブジェクト]
# 1 行が長くなる場合は上のように改行した方が分かりやすい
# さらに内側にループがある場合は同じように続けて書く
実際に先の例を内包表記に置き換えたのが以下のコードです。
points = [[x, y] for x in range(3)
for y in range(3)]
print(points)
[[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
for-in はいくつでも書くことができますが、あまり多重度が増えるとリストの構造自体が複雑になり、コードの可読性も下がりますので、二重ループまででとどめておくのが良いでしょう。
6-3. 条件に一致する場合のみ要素として追加する#
リストに要素を追加する前に、その値が特定の条件を満たすかどうかを判定し、条件を満たさない場合は追加しないように制御するケースを考えてみましょう。以下の例では、外側ループの変数 x の値が内側ループの変数 y の値以下であるときだけ、[x, y] のオブジェクトをリストに追加するよう制御しています。
points = []
for x in range(3):
for y in range(3):
# x が y 以下の場合のみリストに要素を追加する
if x <= y:
points.append([x, y])
このようなコードも内包表記で表現することができます。この場合は、[] 内の最後に、 if キーワードを書いて条件式を指定します。この条件式の中では、for-in で宣言した変数を利用できます。条件式が成立する場合のみ、その回はリストに要素を追加します。
[ 式 for 変数 in 繰り返し可能オブジェクト if 条件式 ]
実際に先の例を内包表記に置き換えたのが以下のコードです。
points = [[x, y] for x in range(3)
for y in range(3)
if x <= y]
print(points)
# ▲ [[0, 0], [0, 1], [0, 2], [1, 1], [1, 2], [2, 2]]
[[0, 0], [0, 1], [0, 2], [1, 1], [1, 2], [2, 2]]
おわりに#
Python には短い記述でより柔軟なリスト操作ができる仕組みが多数ありました。特に、スライスや内包表記は使い勝手が良く、他の方法よりも記述量が大幅に減らせることがあるため、練習を重ねて、ぜひ使いこなせるようになってください。