集合(set)#
Jupyter Notebook ファイルの準備
このノートを学習するために、「set.ipynb」 という名前で Jupyter Notebook のファイルを作成してください。
このノートの練習問題
内容を一通り確認できたら、以下の練習問題に取り組むことでご自身の理解度をチェックしてください。
練習問題:練習問題:集合 | データ構造
集合は、端的に言うと「重複しないデータの集まり」です。リストやタプルと違い、要素間に順序性はなく、また、等しい値を持つ要素が集合内に重複することを許可しません。そのため、純粋なデータの集まりを表すのに都合が良いデータ構造です。
1. 集合の基本操作#
1-1. 集合を作成する#
集合は、次のように、{} 内にカンマ区切りで要素を指定するリテラルで作成します。ただし、要素の記述順は集合オブジェクトの作成に影響しません。
{要素1, 要素2, 要素3, ...}
{} # 左は空の集合ではなく、空の辞書として扱われることに注意
例えば、関東地方の都道府県の集合は以下のようにして作成できます。
Kanto_prefectures = {"Ibaraki", "Tochigi", "Gunma", "Saitama", "Chiba", "Tokyo", "Kanagawa"}
print(Kanto_prefectures)
# ▲ {'Chiba', 'Tochigi', 'Gunma', 'Kanagawa', 'Ibaraki', 'Tokyo', 'Saitama'}
# 順序をもたないため、宣言時のデータの並びと出力時のデータの並びが必ずしも一致しない
{'Tokyo', 'Saitama', 'Gunma', 'Kanagawa', 'Chiba', 'Ibaraki', 'Tochigi'}
ただし、要素を指定せずに書いた空の {} は、後のノートで説明する空の「辞書」型のオブジェクトを作成するので気を付けてください。
# 空の {} のリテラルは辞書(dict)型のオブジェクトを作成する
empty_dict = {}
print(type(empty_dict)) # <class 'dict'> ← 辞書型のオブジェクト
# 空の集合を作成した場合は set() と書く
# これは set クラスのコンストラクタを呼び出す
empty_set = set()
print(type(empty_set)) # <class 'set'>
<class 'dict'>
<class 'set'>
集合内には等しい値をもつ要素が重複して存在することはできません。そのため、リテラルで等しい値をもつ要素を複数指定した場合、ふたつめ以降は無視されます。
# 以下の集合を表すリテラルには 'apple' が2度出現しているが重複する要素は無視される
fruits = {'apple', 'banana', 'strawberry', 'apple', 'peach'}
print(fruits) # {'banana', 'apple', 'peach', 'strawberry'}
{'apple', 'strawberry', 'banana', 'peach'}
ここで言う重複とは「等しい値をもつ」ことであり、「同一のオブジェクトである」という意味ではないので注意してください。以下の例では、等しい要素をもつ 2 つのタプルを用意し、それらを要素としてもつ集合を作成しています。2 つのタプルは異なるオブジェクトですが、値が等しいために、集合では重複しているものとみなされています。
# 等しい要素をもつ 2 つのタプルを作成
t_1 = ('apple', 'banana', 'strawberry')
t_2 = ('apple', 'banana', 'strawberry')
print(t_1 is t_2) # False ← 2 つのタプルは異なるオブジェクト
# t_1 と t_2 を要素にもつ集合を作成
# しかし、2 つのタプルは値が等しいため重複できず、 t_2 は無視される
fruits = {t_1, t_2}
print(fruits) # {('apple', 'banana', 'strawberry')}
False
{('apple', 'banana', 'strawberry')}
1-2. 集合の長さを取得する#
集合も len 関数で長さ(要素数)を調べることができます。
fruits = {"apple", "banana", "strawberry", "peach"}
print(len(fruits)) # 4
4
1-3. 要素を取得する#
集合の要素間には順序がありません。そのため、リストやタプルのようにブラケット表記法とインデックスを使用して、特定の要素だけを取得することはできません。
一方で、集合も繰り返し可能オブジェクトであるため、for 文を使い、繰り返し要素を取得することができます。
fruits = {"apple", "banana", "strawberry", "peach"}
for fruit in fruits:
print(fruit)
apple
strawberry
banana
peach
1-4. 要素を追加する#
要素の追加は add(element) メソッドで行えます。
vehicles = set() # 要素を持たない空の集合を作成
vehicles.add('bicycle')
vehicles.add('bike')
vehicles.add('car')
print(vehicles) # {'bicycle', 'bike', 'car'}
{'bicycle', 'car', 'bike'}
ただし、リテラルと同様に、既に等しい値をもつ要素が存在する場合は追加されません。
vehicles = set()
vehicles.add('bicycle')
vehicles.add('bike')
vehicles.add('bike') # この追加命令は無視される
vehicles.add('bike') # この追加命令は無視される
vehicles.add('car')
print(vehicles) # {'bicycle', 'bike', 'car'}
{'bicycle', 'car', 'bike'}
他には update(other) メソッドで、別の集合がもつすべての要素を、新たな要素として追加することができます。このメソッドも既に重複する要素がある場合は追加されません。
my_friends = {"Taro", "Kenji", "Shou"}
new_friends = {"Rin", "Kana", "Chika"}
my_friends.update(new_friends)
print(my_friends) # {'Taro', 'Shou', 'Kenji', 'Kana', 'Chika', 'Rin'}
{'Taro', 'Kenji', 'Shou', 'Rin', 'Kana', 'Chika'}
1-5. 要素を削除する#
インデックスを使用した要素へのアクセスができないため、リストのようなブラケット表記法と del 命令による要素の削除はできません。代わりに、 remove(element) メソッドを使用します。このメソッドは引数に指定したオブジェクトと等しい値を持つ要素を集合から削除します。
fruits = {"apple", "banana", "strawberry", "peach"}
fruits.remove("apple")
print(fruits) # {'strawberry', 'banana', 'peach'}
{'strawberry', 'banana', 'peach'}
remove 以外には、次のメソッドで要素を削除できます。
discard(element): 引数に指定したオブジェクトと等しい値を持つ要素を削除します。pop(): 任意の要素を削除して、その要素を返します。clear(): 集合が持つすべての要素を削除します。
remove と discard の違いは、該当する要素がないときに、 remove は例外の KeyError を送出しますが、 discard は例外を送出しない点にあります。
discardメソッドを用いた要素の削除
fruits = {"apple", "banana", "strawberry", "peach"}
fruits.discard("apple")
fruits.discard("onion") # 何も起きない
print(fruits) # {'strawberry', 'banana', 'peach'}
{'strawberry', 'banana', 'peach'}
removeメソッドを用いた要素の削除
fruits = {"apple", "banana", "strawberry", "peach"}
fruits.remove("apple")
# 以下の行を有効にすると KeyError が送出される
# fruits.remove("onion")
print(fruits)
{'strawberry', 'banana', 'peach'}
popメソッドを用いた要素の削除
# pop は任意の要素をひとつだけ削除して、その要素を返す
# 任意の要素であるため、常に同じ結果になるとは限らない
fruits = {"apple", "banana", "strawberry", "peach"}
removed_fruit = fruits.pop()
print(removed_fruit, fruits)
apple {'strawberry', 'banana', 'peach'}
clearメソッドを用いた要素の削除
# clear はすべての要素を削除する
fruits = {"apple", "banana", "strawberry", "peach"}
fruits.clear()
print(fruits) # set() ← 空の集合を表している
set()
1-6. 等しい値をもつ要素が集合に含まれているかどうかを調べる#
等しい値を持つ要素が集合に含まれているかどうかを調べたいときは、リストやタプルと同様に in 演算子や not in 演算子が使用できます。
fruits = {"apple", "banana", "strawberry", "peach"}
print("banana" in fruits) # True
print("onion" in fruits) # False
print("banana" not in fruits) # False
print("onion" not in fruits) # True
True
False
False
True
1-7. 集合に格納できる要素の条件#
集合に格納できる要素は ハッシュ可能(hashable) を満たすオブジェクトでなければなりません。ハッシュ可能とはオブジェクトからハッシュ値が計算できることを指しています。ハッシュ値とは端的に言えば「データから計算される固定長の数値」です。同一のデータからは常に一意なハッシュ値が求まるという特性があります。
ハッシュ可能なオブジェクトのハッシュ値は、Python に標準で組み込まれている hash 関数で取得できます。
print(hash("abcde"))
-2922340846327497787
Python では文字列以外にも以下のオブジェクトがハッシュ可能です。一度作成したら、そのオブジェクトがもつデータが変わらない、言い換えると、データが固定化されているのが特徴です。
ハッシュ可能なオブジェクト例:数値(整数、浮動小数点数)、文字列、論理値
特定の条件下でのみハッシュ可能なオブジェクト:タプル
一方で次のオブジェクトはハッシュ不可です。
ハッシュ不可なオブジェクト例:リスト、集合、辞書
リストや集合は、要素の追加や更新、削除ができるという可変な性質がありました。そのため、データが固定化できず、同じオブジェクトであっても常に一意なハッシュ値を求めることができません。
タプルについては、少しだけ特殊です。タプル自体は不変であるため、一見するとハッシュ可能なように思えます。しかし、タプルがもつ要素の中に、リストや集合のようなハッシュ不可なオブジェクトが存在する場合は、データが固定化されていないため、そのタプルはハッシュ不可となります。つまり、タプルはすべての要素がハッシュ可能である場合にのみハッシュ可能となります。
hashable_tuple = (1, (2, 3, 4))
unhashable_tupele = (1, [2,3,4])
print(hash(hashable_tuple)) # ハッシュ値が求まる
# 以下を有効にすると、TypeError が送出される
# print(hash(unhashable_tupele))
1263151450312643629
2. 集合をきちんと理解する#
前のセクションでは、集合の作成の仕方や、基本的な操作方法を説明しました。一方で、より集合を使いこなすためには、そもそも数学的な集合の概念についての理解が不可欠です。このセクションを通して、改めて集合について復習しましょう。
2-1. 空集合#
要素をひとつも持たない集合のことを 空集合(くうしゅうごう) と言います。引数なしで set クラスのコンストラクタを呼び出して作成されるのは、この空集合のオブジェクトです。
empty_set = set()
print(len(empty_set)) # 0
0
2-2. 等価な集合#
ある集合Aとある集合Bが全く同じ要素から構成されているとき「集合Aと集合Bは等しい」と言います。Python では 2 つの集合が等しいかどうかは、比較演算子の == や != で評価できます。
set_a = {1, 2, 3, 4} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {3, 4, 5, 6} # 集合C
print(set_a == set_b) # True: 集合Aと集合Bは等しい
print(set_a is set_b) # False: 同一オブジェクトであることと等しい集合であることは別
print(set_a != set_c) # True: 集合Aと集合Bは等しくない
True
False
True
2-3. 部分集合#
ある集合Aがもつすべての要素が、別の集合Bにすべて含まれている場合、「集合Aは集合Bの部分集合である」と言います。Python では、比較演算子の <= または集合の issubset() メソッドで調べることができます。
set_a = {1, 2, 3} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {2, 3, 4, 5} # 集合C
print(set_a <= set_b) # True: 集合A は 集合B の部分集合である
print(set_a.issubset(set_b)) # True
print(set_a <= set_c) # False: 集合A は 集合B の部分集合でない
print(set_a.issubset(set_c)) # False
True
True
False
False
部分集合の定義には、等しい集合であるときも含まれます。等しい集合を除いた部分集合は 真部分集合 と言います。真部分集合であるかどうかは比較演算子の < で調べることができます。
set_a = {1, 2, 3} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {1, 2, 3, 4} # 集合C
print(set_a < set_c) # True: 集合A は 集合C の真部分集合である
print(set_b < set_c) # False: 集合B は 集合C の真部分集合ではない
print(set_b <= set_c) # True: 集合B は 集合C の部分集合である
True
False
True
2-4. 上位集合#
集合A が 集合B の部分集合であるとき、逆の視点では「集合B は 集合A の上位集合である」と言います。兄弟や姉妹の関係と同じように、結果としては同じ状態を表していますが、視点が違うと呼び方も変わります。Python では >= 演算子または issuperset() メソッドで上位集合かどうかを調べることができます。
set_a = {1, 2, 3} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {2, 3, 4, 5} # 集合C
print(set_b >= set_a) # True: 集合B は 集合A の上位集合である
print(set_b.issuperset(set_a)) # True
print(set_c >= set_a) # False: 集合C は 集合A の上位集合でない
print(set_c.issuperset(set_a)) # False
True
True
False
False
上位集合の定義には、等しい集合であるときも含まれます。等しい集合を除いた上位集合は 真上位集合 と言い、比較演算子の > で調べることができます。
set_a = {1, 2, 3} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {1, 2, 3, 4} # 集合C
print(set_c > set_a) # True: 集合C は 集合A の真上位集合である
print(set_c > set_b) # False: 集合C は 集合B の真上位集合でない
print(set_c >= set_b) # True: 集合C は 集合B の上位集合である
True
False
True
2-5. 互いに疎である集合#
集合A と 集合B が互いにひとつも共通する要素を持たない場合、「集合A と 集合B は互いに疎である」と言います。Python では isdisjoint() メソッドで 2 つの集合が互いに疎であるかどうかを調べることができます。
set_a = {1, 2, 3} # 集合A
set_b = {4, 5, 6} # 集合B
set_c = {6, 7, 8} # 集合C
print(set_a.isdisjoint(set_b)) # True: 集合A と 集合B は互いに疎である
print(set_b.isdisjoint(set_c)) # False: 集合B と 集合C は共通部分をもつ
True
False
3. 集合演算#
数値の計算と同じように、2つの集合どうしの「和」「差」「積」を求めることができます。集合の和と差については、数値の足し算、引き算と似ていますが、集合の積は数値の掛け算とは全く異なる考え方をするため注意してください。
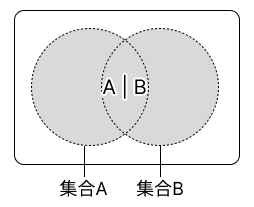
3-1. 和集合#
2 つの集合の和集合は、 2 つの集合がもつ要素をすべてもつ集合です。和集合は、縦線を表す記号である | を用いた演算子で表します。
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
union_set_a_and_b = set_a | set_b
print(union_set_a_and_b) # {1, 2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6}
| 演算子を使う他にも、集合の union() メソッドや update() メソッドを利用して和集合を表すこともできます。 union() は和集合を表すオブジェクトを新たに作成して返すのに対して、 update() メソッドは呼び出し元の集合に結果を反映するという違いがあります。
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
set_c = {5, 6, 7, 8} # 集合C
# union() メソッドで表した和集合
union_set_a_and_b = set_a.union(set_b) # 新しい集合が作成される
print(union_set_a_and_b) # {1, 2, 3, 4, 5, 6}
print(set_a) # {1, 2, 3, 4} ← 呼び出し元の集合は変更されない
# update() メソッドで表した和集合
set_b.update(set_c)
print(set_b) # {3, 4, 5, 6, 7, 8} ← 結果を反映するかたちで呼び出し元の集合を更新する
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4}
{3, 4, 5, 6, 7, 8}
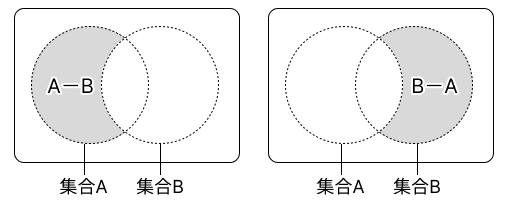
3-2. 差集合#
2 つの集合の差集合は、一方の集合からもう一方の集合がもつ要素を取り除いた集合です。差集合は - 演算子または集合の difference() メソッドで表します。数値の引き算と同様に、どちらからどちらを引くかで結果が異なるので気を付けてください。
# - 演算子で表した差集合
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
set_a_minus_b = set_a - set_b # A-B
set_b_minus_a = set_b - set_a # B-A
print(set_a_minus_b) # {1, 2}
print(set_b_minus_a) # {5, 6}
{1, 2}
{5, 6}
# difference() メソッドで表した差集合
set_a = {1, 2, 3, 4} # 集合A
set_b = {1, 2, 3, 4} # 集合B
set_c = {3, 4, 5, 6} # 集合C
set_a_minus_c = set_a.difference(set_c) # 集合A - 集合C を表す
print(set_a_minus_c) # {1, 2}
print(set_a) # {1, 2, 3, 4} ← このメソッドは呼び出し元の集合を変更しない
# 類似の defference_update() メソッドは呼び出し元の集合を変更する
set_b.difference_update(set_c) # 集合B - 集合C を表す
print(set_b) # {1, 2} ← 結果を用いて呼び出し元の集合を更新する
{1, 2}
{1, 2, 3, 4}
{1, 2}
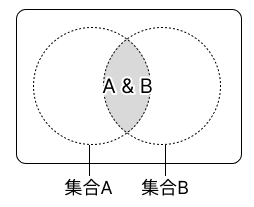
3-3. 積集合#
2 つの集合の積集合は、両方に共通する要素のみを集めた集合です。積集合は & 演算子または集合の intersection() メソッドで表します。
# & 演算子で表した積集合
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
intersection_set_a_and_b = set_a & set_b
print(intersection_set_a_and_b)
{3, 4}
# intersection() メソッドで表した積集合
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
set_c = {5, 6, 7, 8} # 集合C
intersection_set_a_and_b = set_a.intersection(set_b) # 集合A & 集合B を表す
print(intersection_set_a_and_b) # {3, 4}
print(set_a) # {1, 2, 3, 4} ← このメソッドは呼び出し元の集合を変更しない
# 類似の intersection_update() メソッドは呼び出し元の集合を変更する
set_b.intersection_update(set_c) # 集合B & 集合C を表す
print(set_b) # {5, 6} ← 結果を用いて呼び出し元の集合を更新する
{3, 4}
{1, 2, 3, 4}
{5, 6}
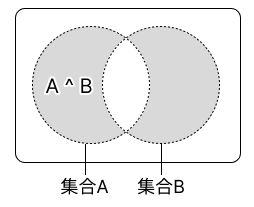
3-4. 対称差#
2 つの集合の対称差は、どちらか一方の集合のみに存在する要素だけを集めた集合です。対称差は ^ 演算子または集合の symmetric_difference() メソッドで表します。
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
symmetric_difference = set_a ^ set_b
print(symmetric_difference) # {1, 2, 5, 6}
{1, 2, 5, 6}
# symmetric_difference() メソッドで表した積集合
set_a = {1, 2, 3, 4} # 集合A
set_b = {3, 4, 5, 6} # 集合B
set_c = {5, 6, 7, 8} # 集合C
symmetric_difference_set_a_and_b = set_a.symmetric_difference(set_b) # 集合A ^ 集合B を表す
print(symmetric_difference_set_a_and_b) # {1, 2, 5, 6}
print(set_a) # {1, 2, 3, 4} ← このメソッドは呼び出し元の集合を変更しない
# 類似の symmetric_difference_update() メソッドは呼び出し元の集合を変更する
set_b.symmetric_difference_update(set_c) # 集合B ^ 集合C を表す
print(set_b) # {3, 4, 7, 8} ← 結果を用いて呼び出し元の集合を更新する
{1, 2, 5, 6}
{1, 2, 3, 4}
{3, 4, 7, 8}
4. 集合の内包表記#
リストと同様に、集合にも内包表記があります。基本的な構造は同じですが、外側を [] ではなく、 {} で囲みます。
{ 式 for 変数 in 繰り返し可能オブジェクト}
# ▼ 追加の条件を指定する場合も、同じく if キーワードと条件式を最後に記述する
{ 式 for 変数 in 繰り返し可能オブジェクト if 条件式}
以下の例では、1 から 99 までの数のなかで「 3 の倍数である数の集合」と「 5 の倍数である数の集合」をそれぞれ内包表記で作成しています。さらに & 演算子を用いた積集合で、「3 と 5 の公倍数の集合」を求める処理も行っています。
# 3 の倍数の集合
multiples_of_3 = {n for n in range(3, 100, 3)}
# {n for n in range(1, 100) if n % 3 == 0} と書いても良い
print(multiples_of_3)
# 5 の倍数の集合
multiples_of_5 = {n for n in range(5, 100, 5)}
# {n for n in range(1, 100) if n % 5 == 0} と書いても良い
print(multiples_of_5)
# 3 と 5 の公倍数の集合
common_multiples_of_3_and_5 = multiples_of_3 & multiples_of_5
print(common_multiples_of_3_and_5)
{3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99}
{5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95}
{75, 45, 15, 90, 60, 30}
おわりに#
集合は重複しないデータの集まりを表すのに適したデータ構造であることを確認しました。例えば、ユーザーが入力した値が、こちらが提示した候補から選択されたものかどうかを調べるときは、リストやタプルよりも、集合を使う方がより適当でしょう。特にユーザーに複数の値を選択させるケースでは、候補の部分集合かどうかを <= 演算子で比較すれば良いだけなので、かなりコードが簡略化できます。
ユーザーが入力した単一の値 in 候補の集合
ユーザーが入力した値の集合 <= 候補の集合
このように、複数のデータをまとめて扱う場合は、リストやタプルをとりあえず使うのではなく、集合の特性がうまく利用できないかどうかも合わせて検討するようにしてください。